Examples#
I. Requests to Servers#
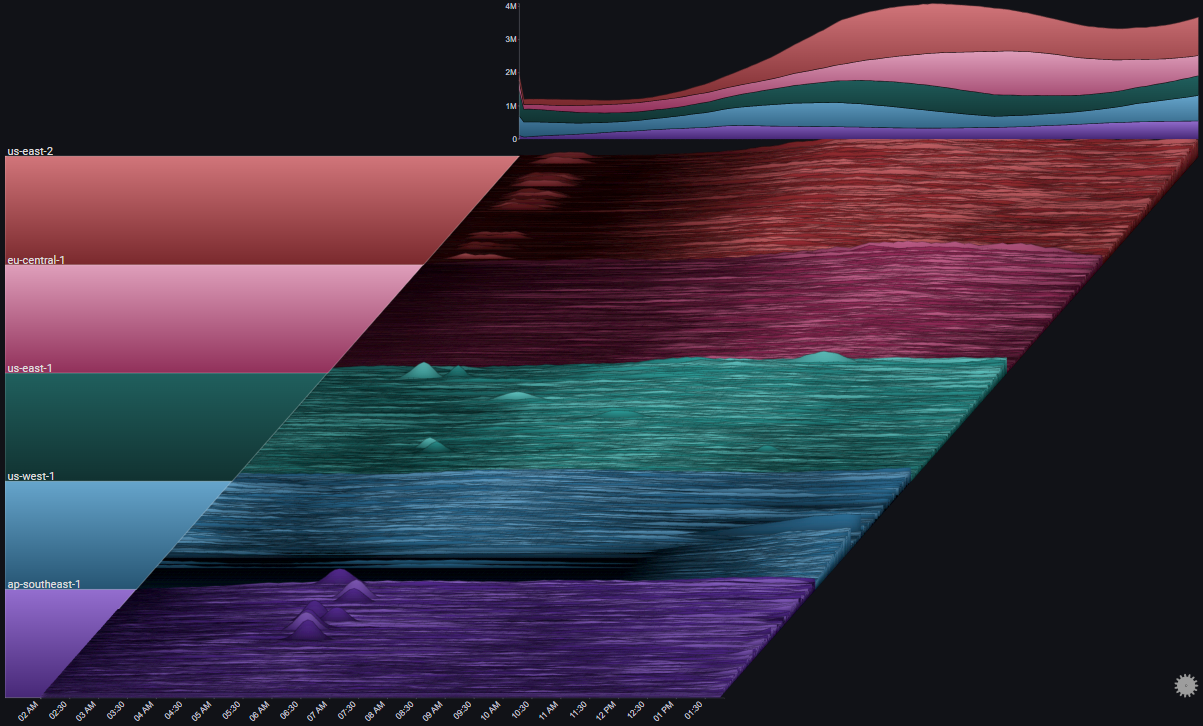
The following example showcases how a Sierra Plot can be used to visualize and analyze a scenario of requests hitting:
- 50 different servers
- in 5 different regions
- over 48 hours
- in 1-minute bins
- split by result type (OK or ERROR)
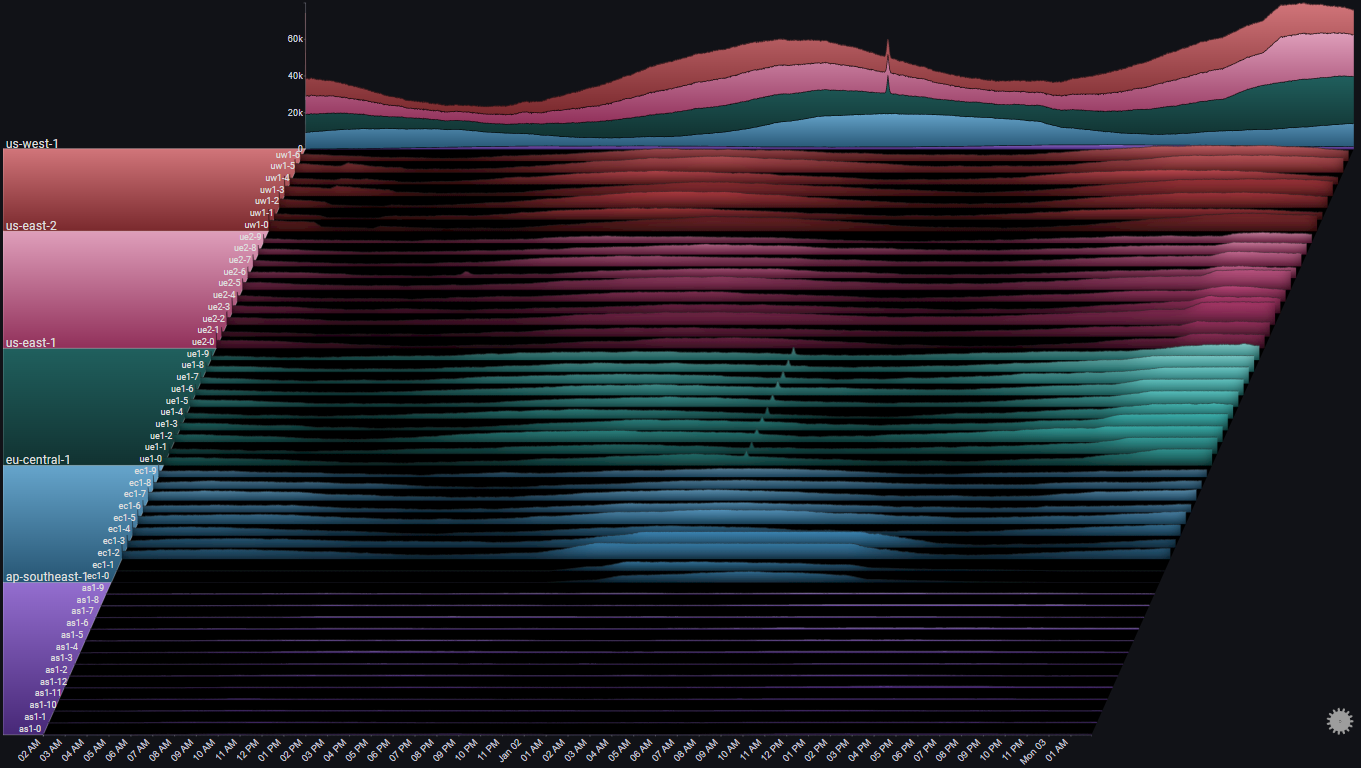
Before diving in, we can make the plot a bit clearer by changing the plot's Max Y Type from Global to Group using the on-panel controls
Hint
Using Max Y Type => Group makes sense here, since comparing individual server metrics across different regions isn't very relevant. The overall comparison across different regions is captured in the Totals chart
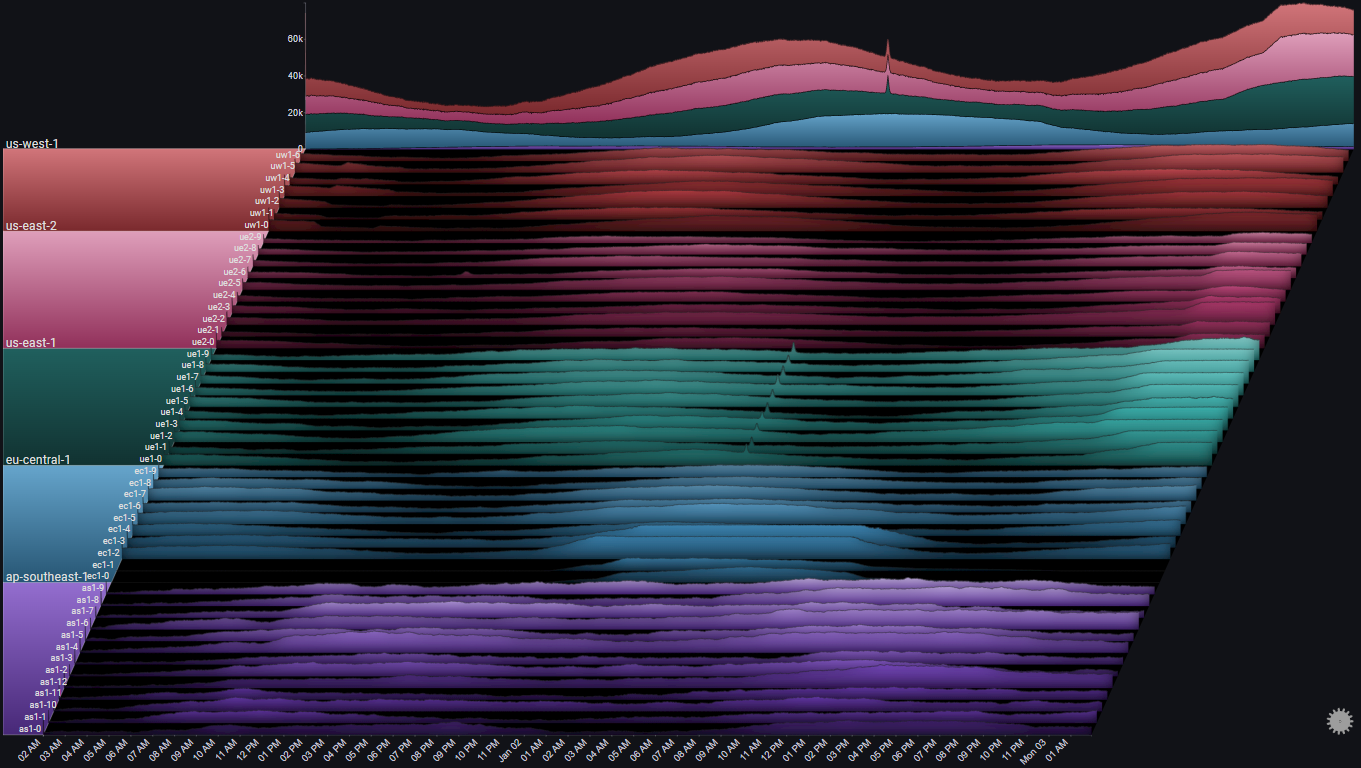
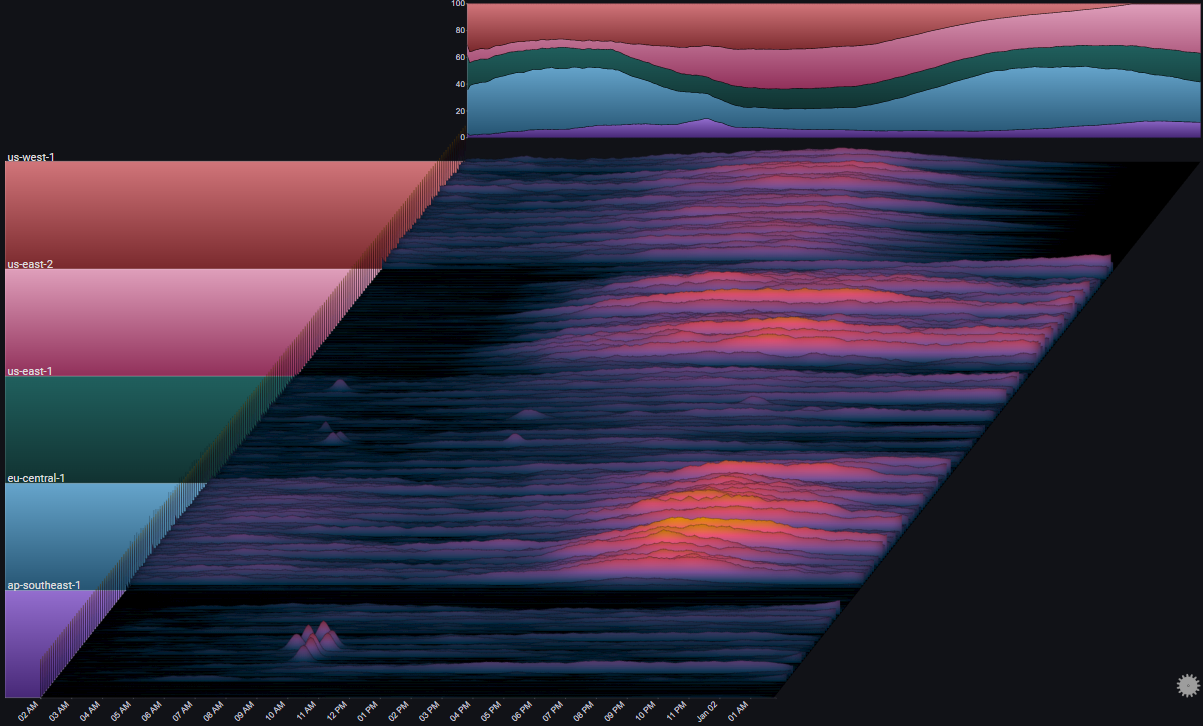
I.I Overview#
I.I.I Overall Trend#
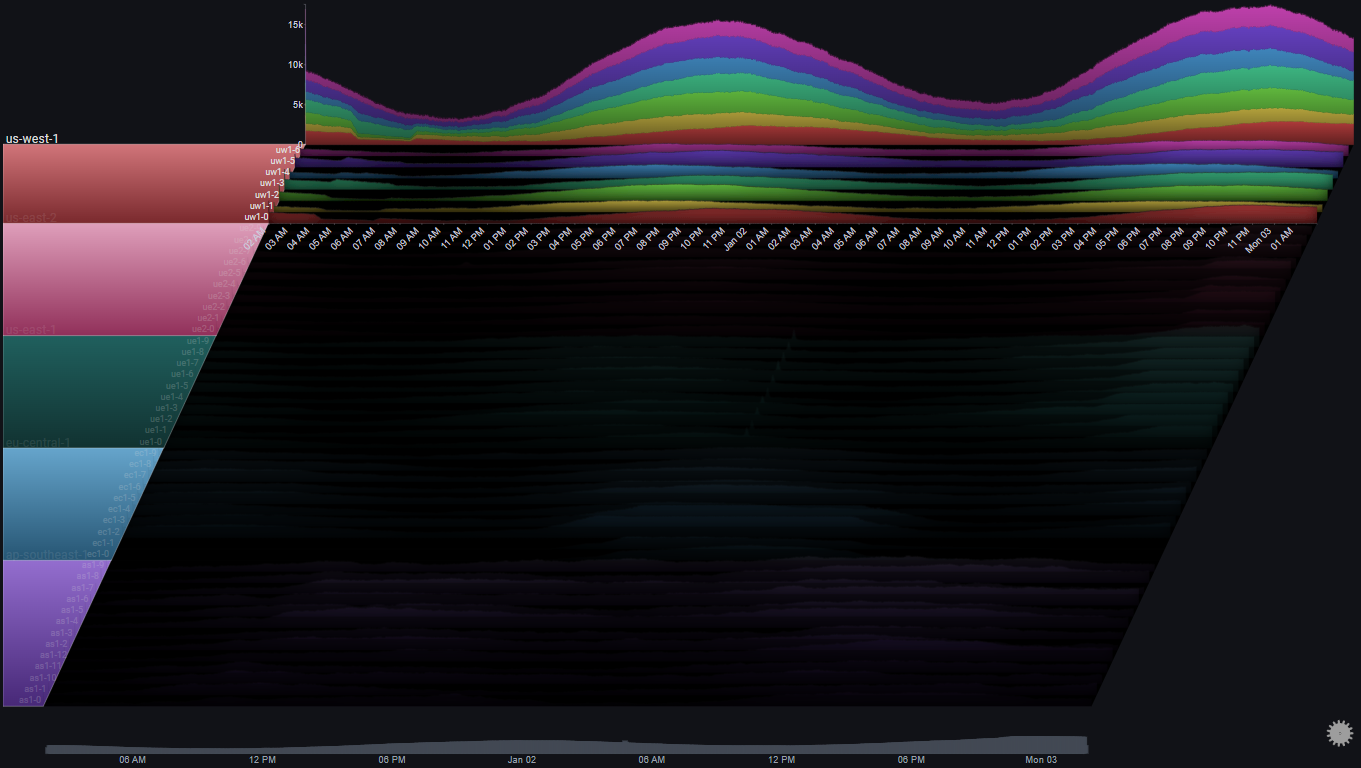
The Totals chart is a simple stacked area chart that clearly shows the overall trend, as well as the per-region breakdown. However, it doesn't do a very good job of showing the indiviual trends for each region.
By changing the Totals Chart Type to Line and playing aroung with the Total Height Percent value, we get:
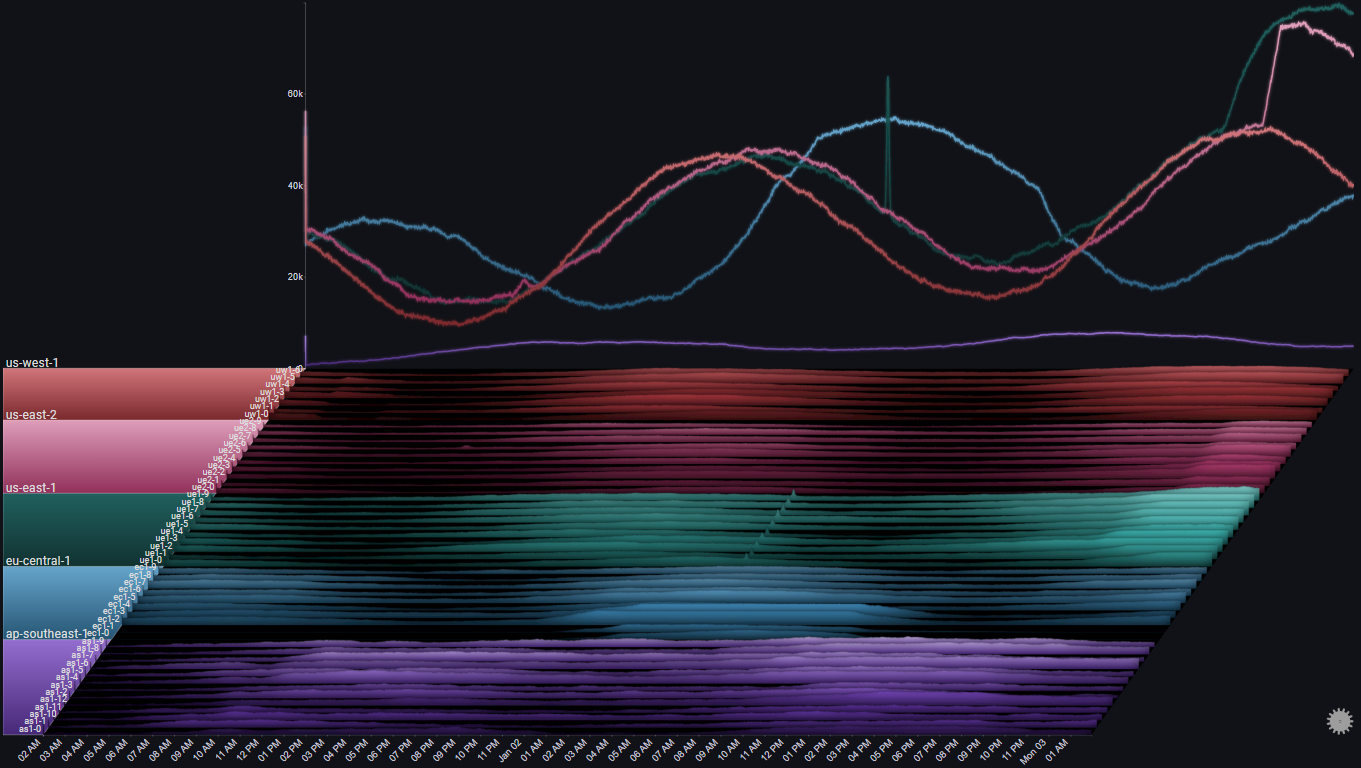
A number of observations become apparent now:
- The trend shows a (baseline) 24 hour cycle in every region
- A certain time shift between the 24 hour cycles for each region (except us-east-1 and us-east-2)
- A huge spike in us-east-1 near the middle of the chart
- An unusual increase in request volume in us-east-1 near the end of the chart
- An unusual increase in request volume in us-east-2 near the end of the chart. Around the same time as in us-east-1, but much steeper
- In eu-central-1 there were two servers which didn't get any traffic at all during most of the 48 hour period
I.I.II Error Trend#
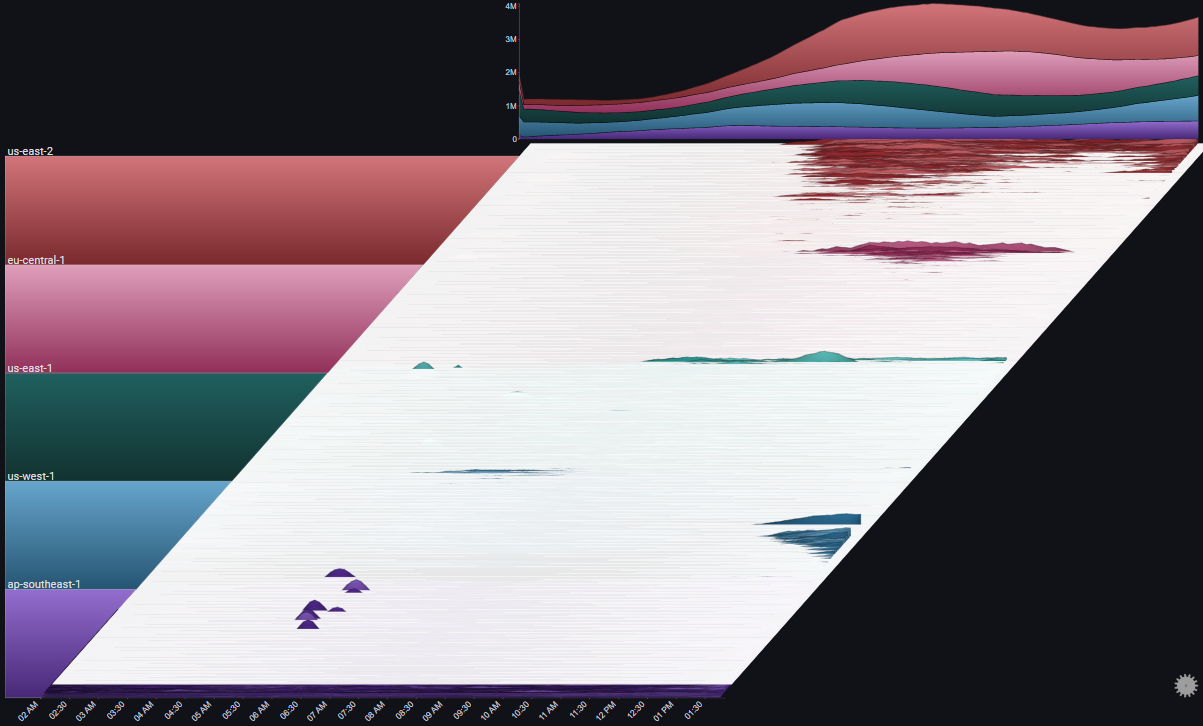
We can see the request count by type (OK or ERROR) by using the Series Breakdown and Totals Breakdown features in the plot's controls:
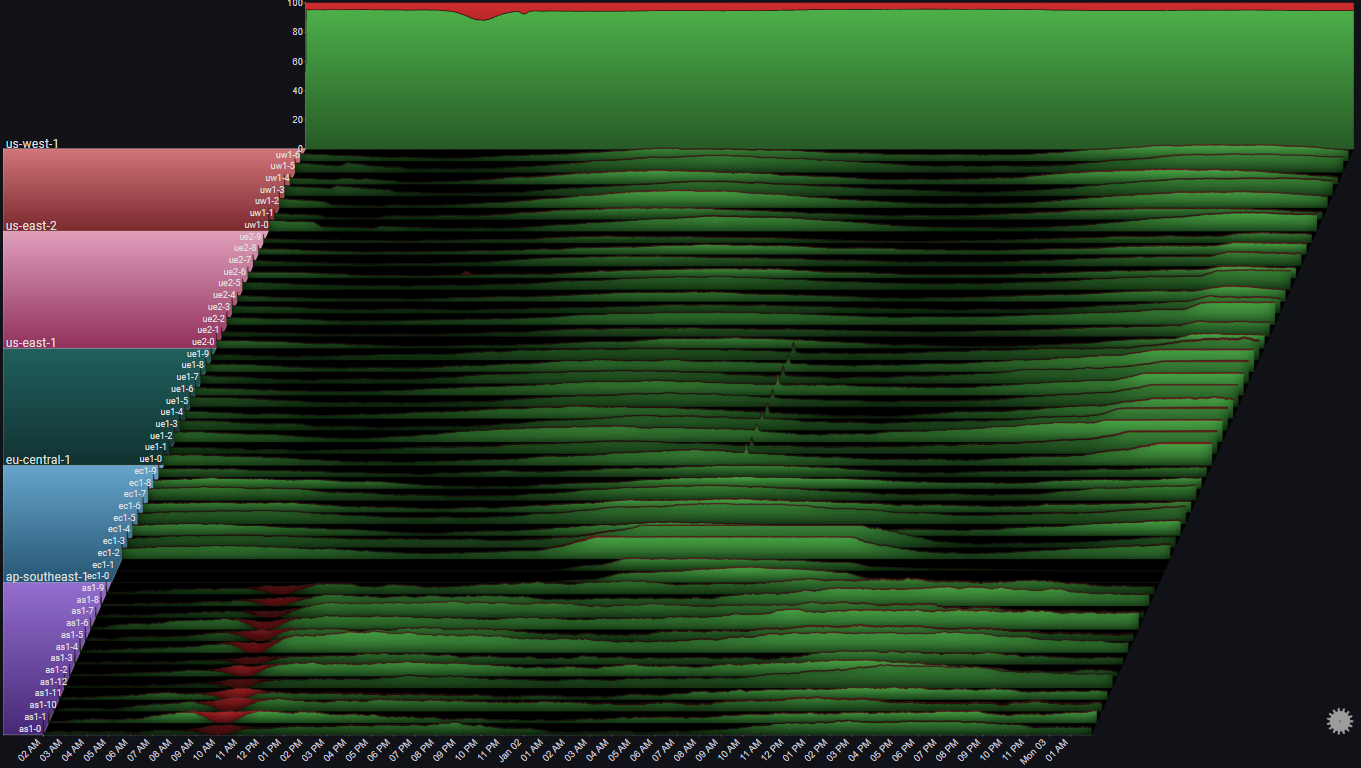
Note
Using Stacked100 for the totals chart, since we usually care more about the relative error rate, and not the absoulte number of errors
We immediately see that the overall error rate is pretty much constant (at 5%) except for two increases, one starting at around 10:00 AM Jan 01, and the second a few hours later
It's also straightforward to attribute the first (bigger) increase to the servers in ap-southeast-1, and the second (smaller) increase to a single server in us-east-2
Before drilling down into the specific issues, let's take one more step just to make sure that we didn't miss anything in our high-level view
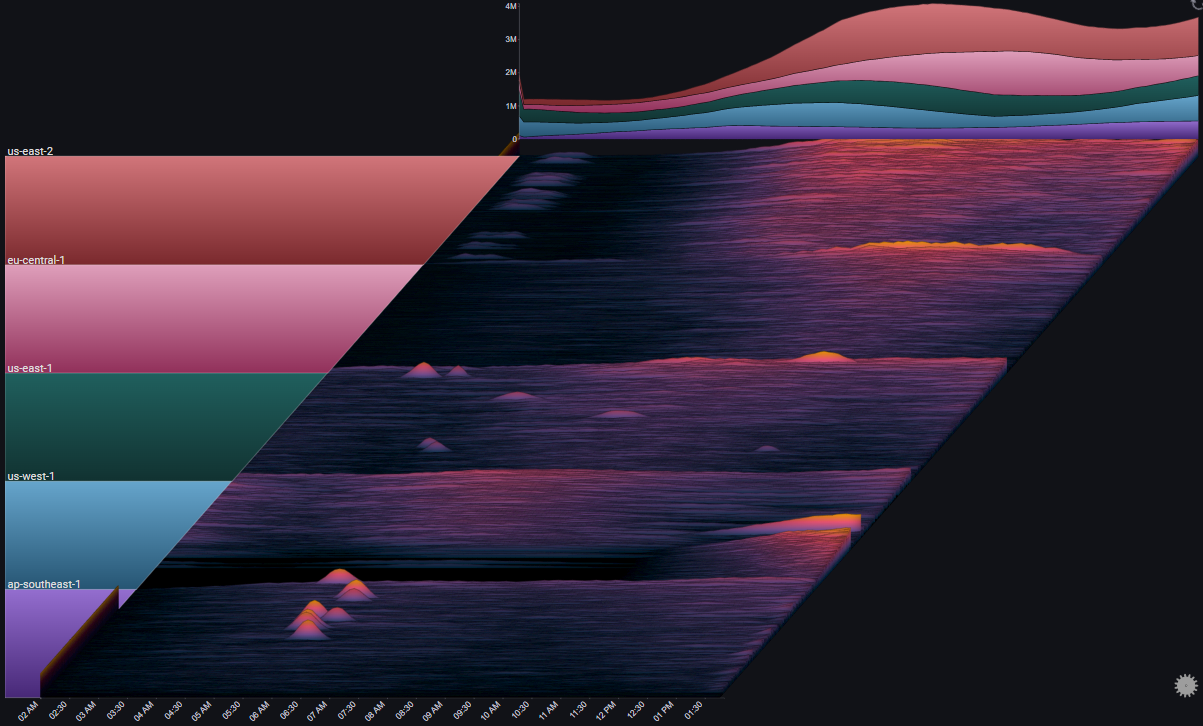
To get a clear picture that specifically targets error rates (as opposed to the volume of requests and their breakdowns) we'll make the following adjustments to the plot's configuration:
- Change the Series Chart Type and Totals Chart Type from Stacked Area Chart to Line Chart
- Set the Total field as the plot's Weight Field
- Set the field value ERROR as the only Series Value
- Change the value of Aggregation from Sum to Average
- Set the Color Mode to Values (Inverted)
Note
Instead of the number of requests of each type, the plot now represents the relative error rate Error / Total for each server. The Totals chart represents the weighted error rate across its selected breakdown
 We can now feel confident that we didn't miss anything before (for example, a high error rate during a time where the number of requests is very small, which might not be visible in a stacked area chart)
We can now feel confident that we didn't miss anything before (for example, a high error rate during a time where the number of requests is very small, which might not be visible in a stacked area chart)
I.II Specific Drilldowns#
Now that we have a high-level picture of the systems behaviour over the 48 hour period, we'll drilldown into the specific issues that were spotted and see what kinds of information the plot might surface up
I.II.I Error Spike in us-east-2#
In I.I.II we saw an error spike in us-east-2 at around 12:00 PM on Jan 01
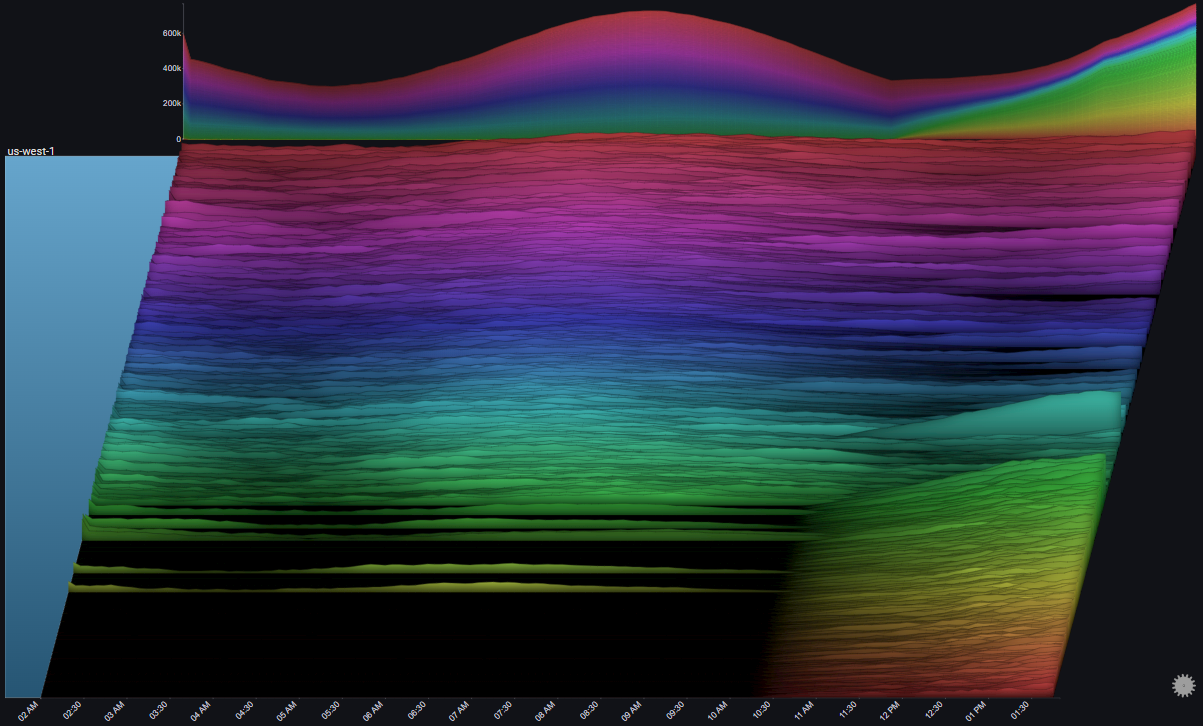
By drilling down on the us-east-2 group and focusing on the specific time around the issue using the date range control we can get a clearer picture of the behavior in us-east-2 at the time of the issue:
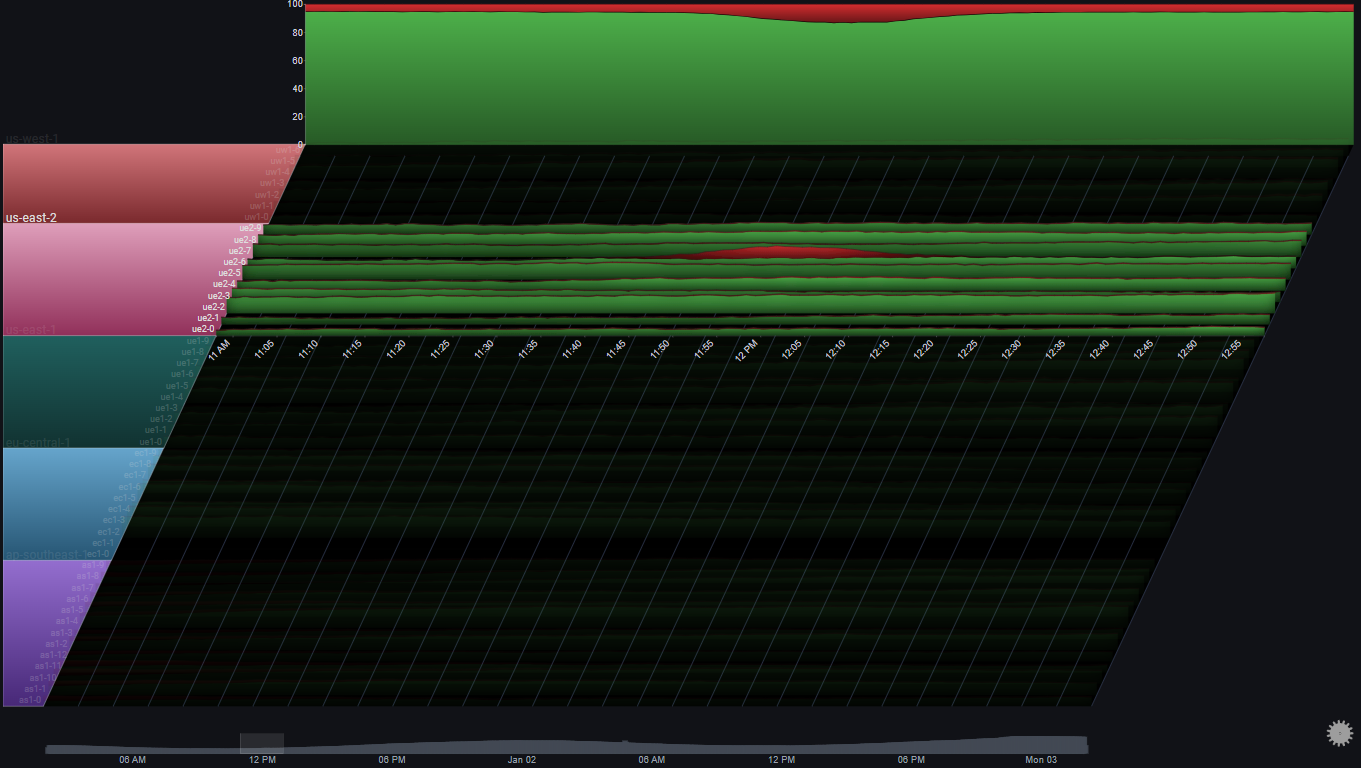
Note
In this example, Gridlines were enabled. They help us connect events in the plot to specific points in time (which might be difficult due to the plot's skew property)
We'll drilldown on us-east-2 again so we can focus on it completely:
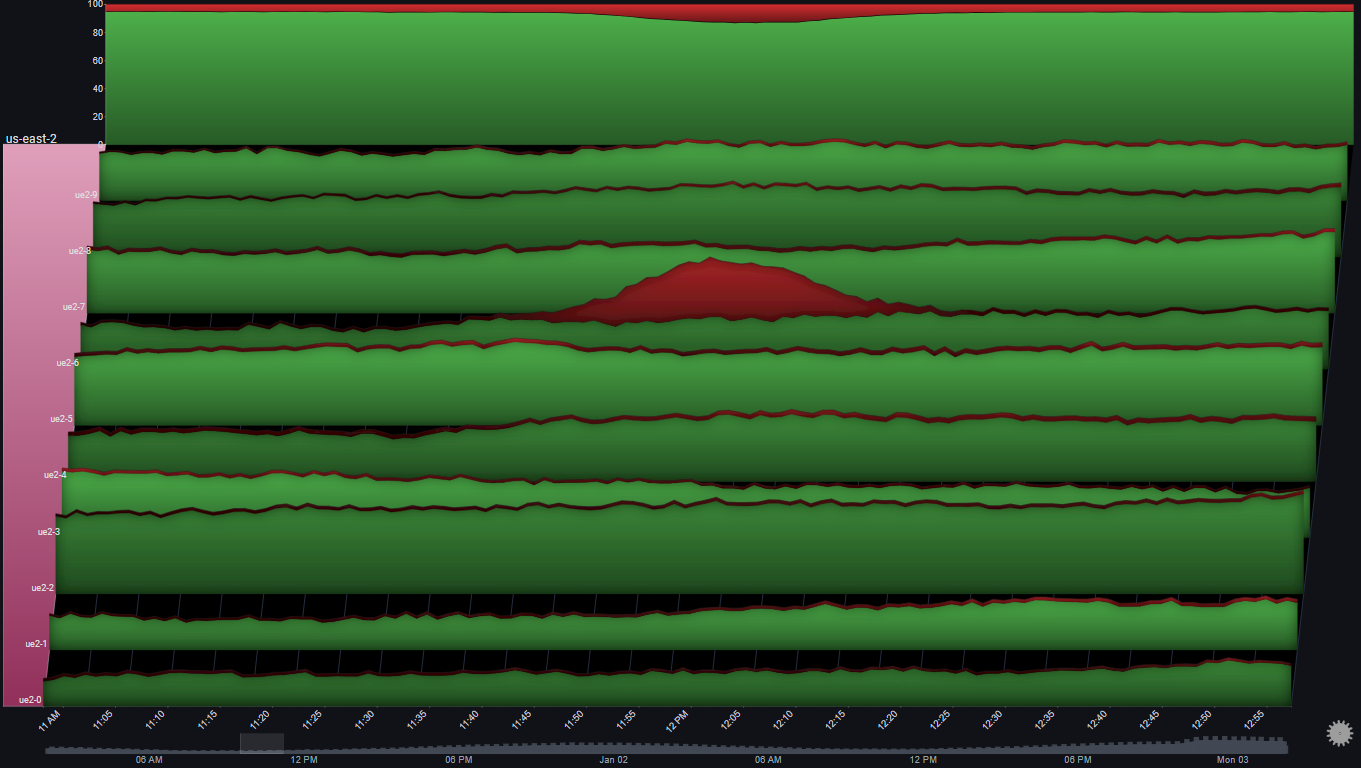
A number of observations become apparent now:
- The issue only happened in one server (ue2-6)
- The effect on the region's overall error rate was an increase from around 5% to around 10%
- The number of requests for all other servers was pretty much constant at the time of the issue
- For the affected server (ue2-6), the number of non-error requests was pretty much constant around the time of the issue
The above observations might lead us to the following conclusions:
- All servers were functioning as expected
- The errors in ue2-6 are due to a specific batch of requests that speficially resulted in errors
- The abnormal requests to ue2-6 did not affect its serving of normal requests
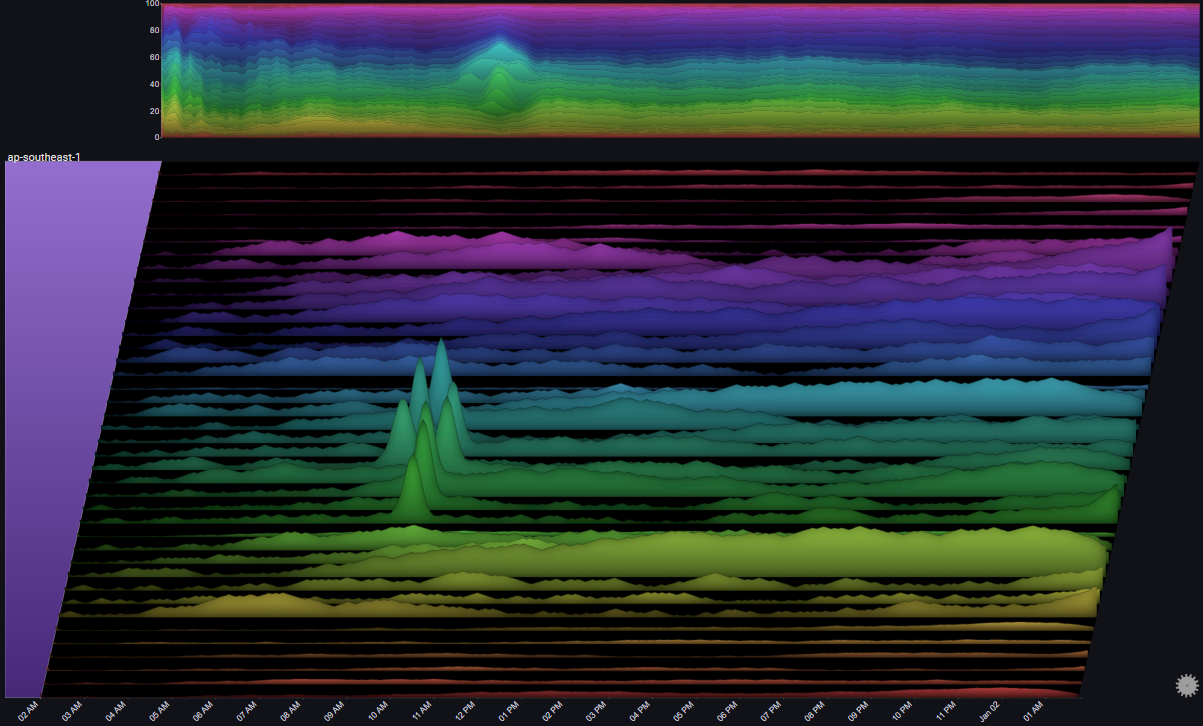
I.II.II Error Spike in ap-southeast-1#
In I.I.II we saw an error spike in ap-southeast-1 at around 10:00 AM on Jan 01
By drilling down on the ap-southeast-1 group we can get a clearer picture of the behaviour of the servers in that region:

A number of observations become apparent now:
- All servers in that region were affected in roughly the same way
- At the peak of the issue, 100% of requests resulted in errors
- The trend in overall number of requests to the servers in ap-southeast-1 was not affected by the issue
The above observations might lead us to the following conclusions:
- The issue (errors) was due to something internal (not due to some change in the requests)
- Since the issue affected all of the servers in the region, and at the same time, there's a good chance that the issue is due to some shared infrastructure component in the region
I.II.III Traffic Routing#
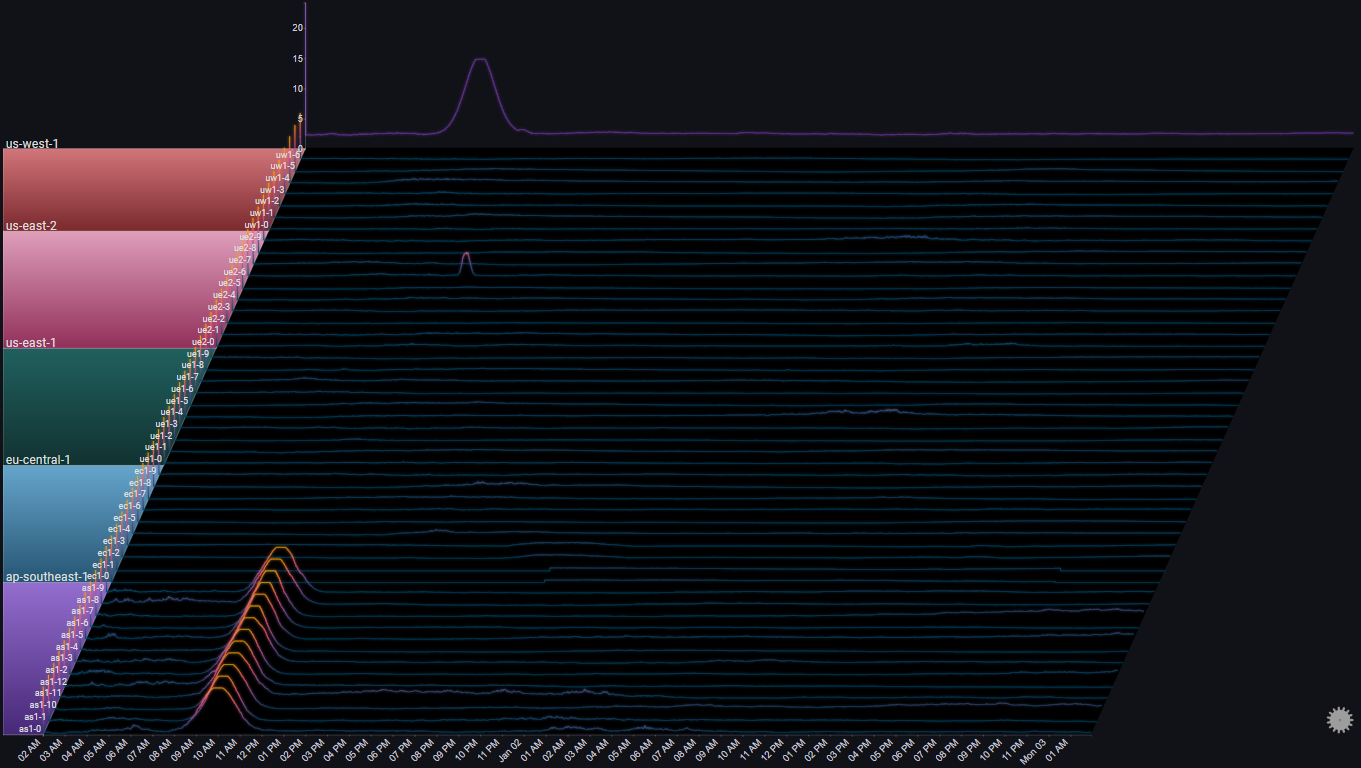
If we look at us-west-1, we can spot something odd happening at around 06:00 AM Jan 01:
 Let's drilldown further:
Let's drilldown further:
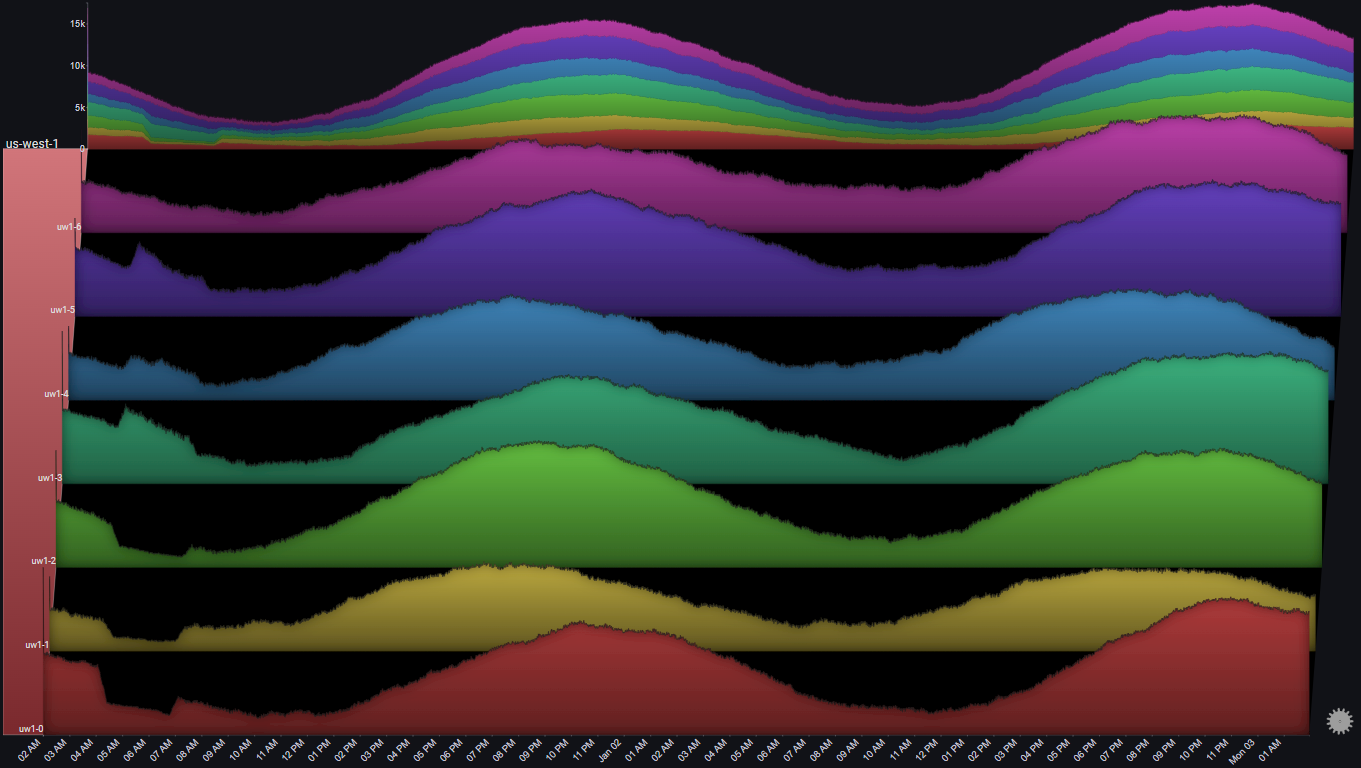 And now let's focus on the specific time range:
And now let's focus on the specific time range:
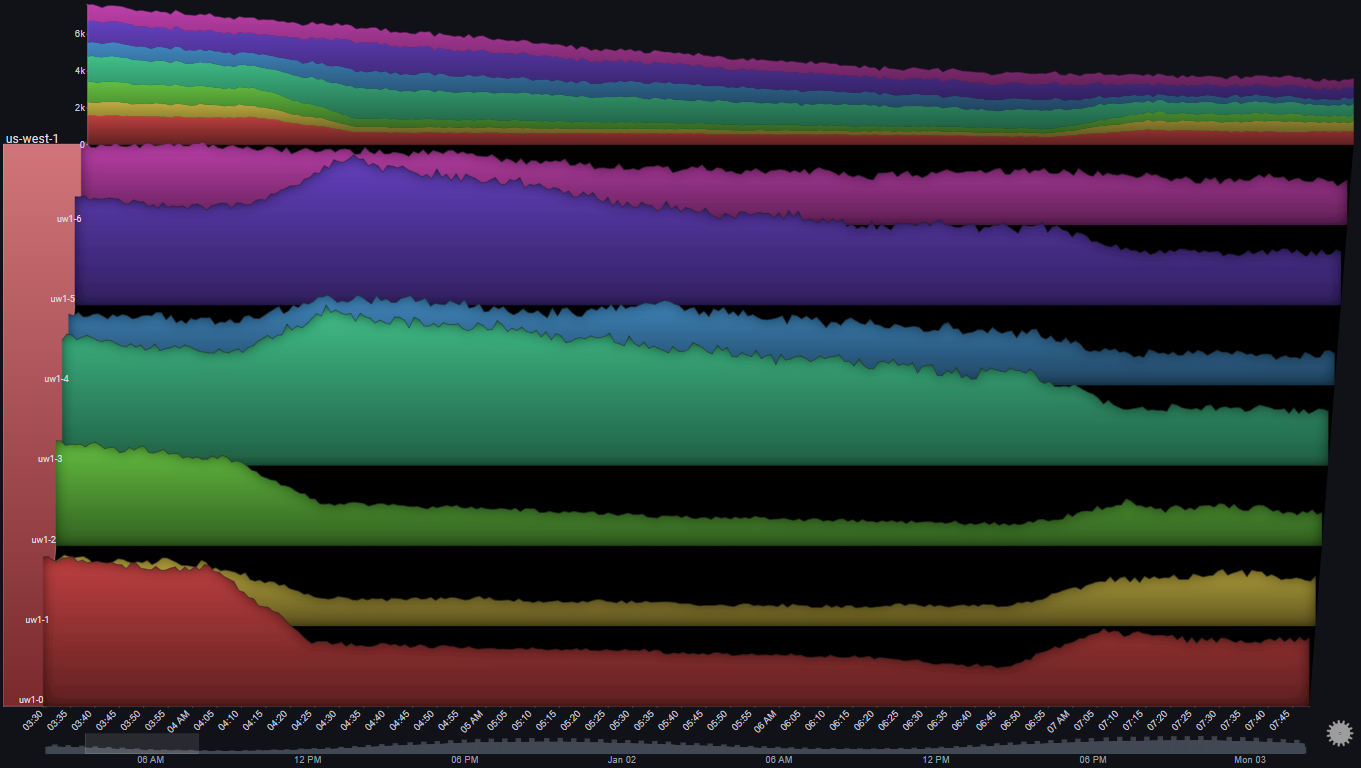
A number of observations become apparent now:
- The number of requests to 3 servers (uw1-0, uw1-1 & uw1-2) dropped between 04:00 AM and 07:00 AM
- The number of requests to 3 servers (uw1-3, uw1-4 & uw1-5) increased at the same time
- The trend in total number of requests to the region did not change during that time period
- While the traffic to uw1-0, uw1-1 & uw1-2 decreased, it did not go to zero
- There was no change in the traffic to usw1-6
The above observations might lead us to the following conclusions:
- Some traffic routing/balancing mechanism shifted some of the traffic from [uw1-0, uw1-1 & uw1-2] to [uw1-3, uw1-4 & uw1-5]
- It doesn't seem like there was some clear issue in the first three servers, since they were still getting traffic and there wasn't an increase in errors
I.II.IV Auto Scaling#
We noticed earlier that in eu-central-1, two servers didn't get any traffic at all during most of the 48 hour period
Let's focus on that region:
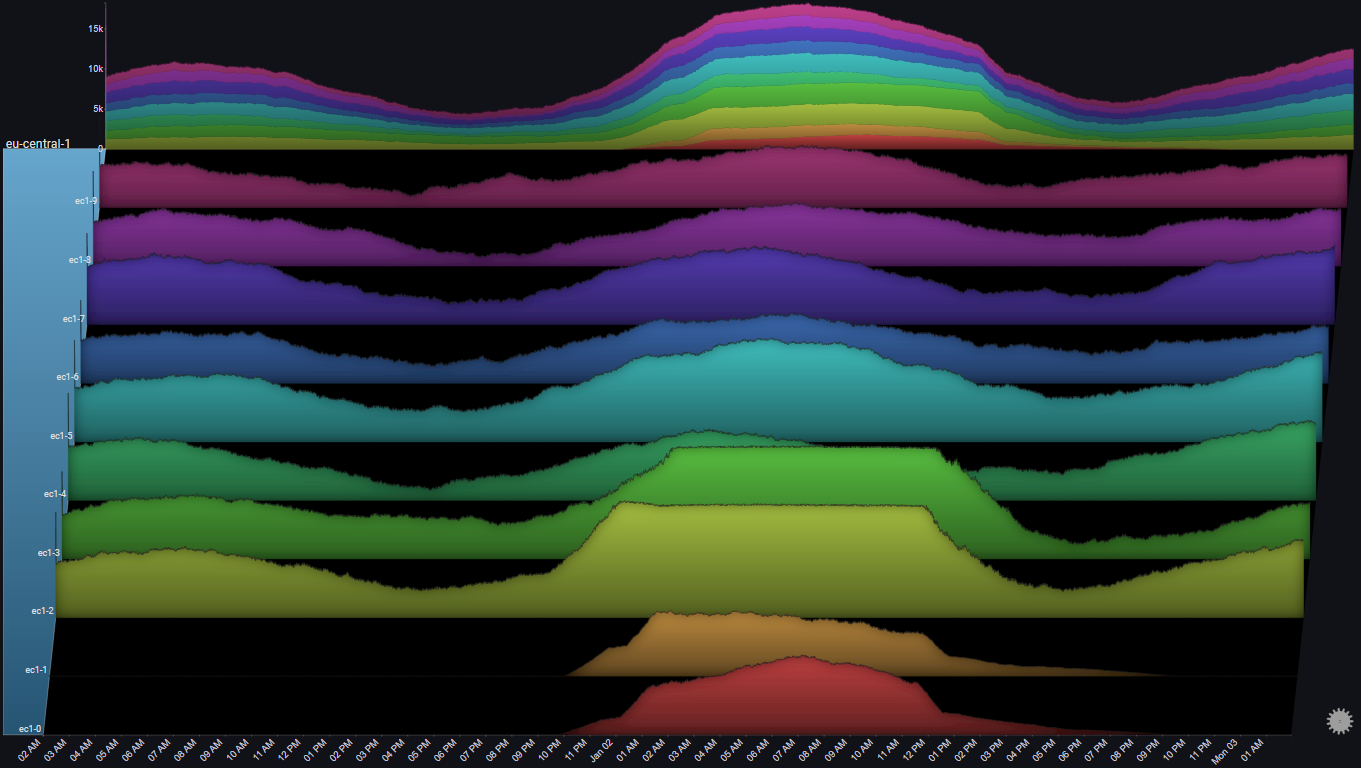
A number of observations become apparent now:
- Two server (ec1-0 & ec1-1) didn't get any requests at all, until Jan 01 at 10:00 PM
- At about the same time, two other servers (ec1-2 & ec1-3) started seeing an increase in the number of requests
- At around 01:00 AM Jan 02, the number of requests to ec1-2 & ec1-3 seems to have plateaued
- At about the same time, the number of requests to ec1-0 & ec1-1 seems to have increased sharply
- After the load on ec1-2 & ec1-3 subsided, traffic was shifted away from ec1-0 & ec1-1 until they were pulled out of rotation completely
The above observations might lead us to the following conclusions:
- When the load on ec1-2 & ec1-3 increased (and passed some threshold), some autoscaling mechanism was triggered
- The autoscaling mechanism added ec1-0 & ec1-1 into rotation and they started getting traffic
- At some point, ec1-2 & ec1-3 reached some capacity threshold, and the LB mechanism maintained that threshold
- Since ec1-2 & ec1-3 were saturated, the LB mechanism started offloading more traffic to ec1-0 & ec1-1
- The asymmetry between the ramp up (fast) and ramp down (slow) of traffic to ec1-0 & ec1-1 might indicate some hysteresis element at play
Let's see if there was any noticeable effect on the amount of errors during that time:
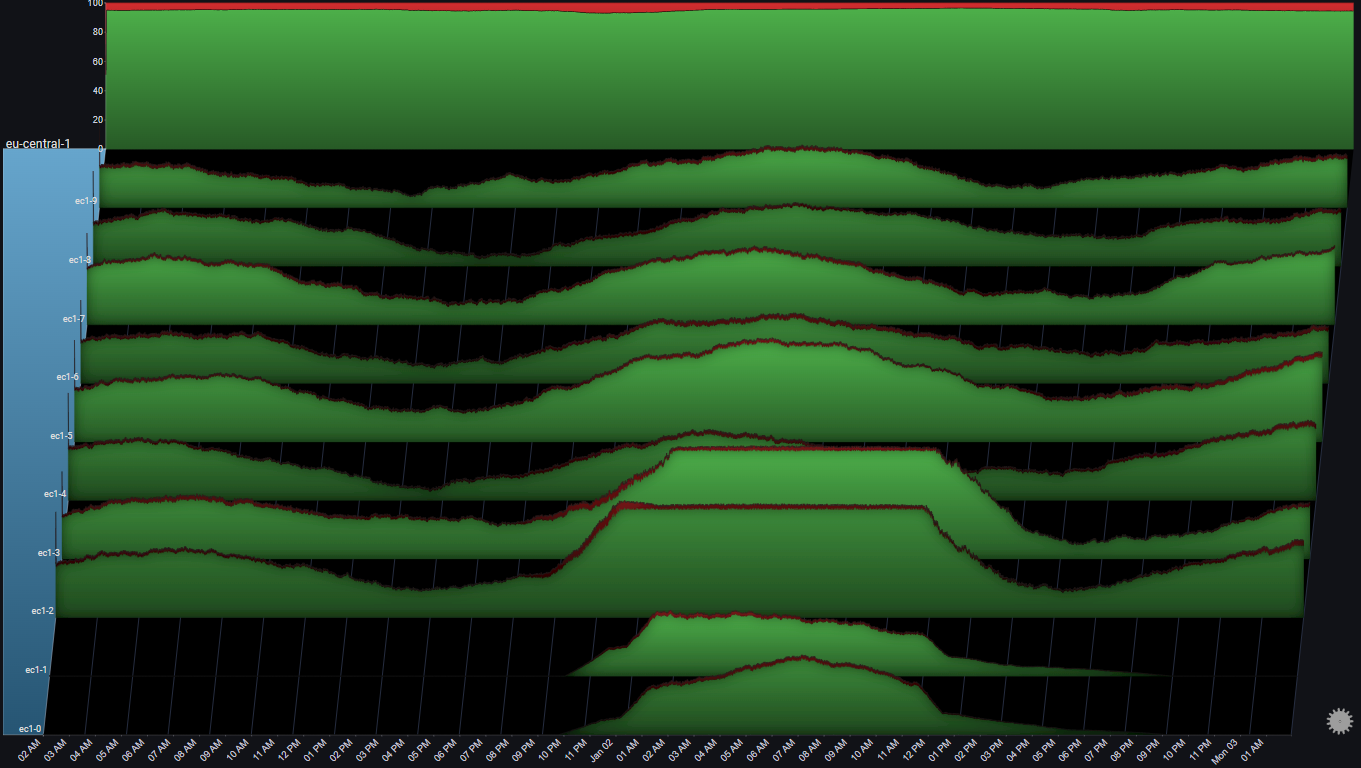
A number of observations become apparent now:
- During the sharp increase in the number of requests to ec1-2 & ec1-3, the error rate in those two servers slightly increased (also noticeable in the total graph for the region)
- Once ec1-0 & ec1-1 were added to the rotation the error rates subsided
The above observations might lead us to the following conclusions:
- Overall, the LB mechanism is functioning properly
- Ideally, the additional servers could be added sooner and prevent the temporary increase in errors
- There's some optimization opportunities to the LB. Specfically, it looks like the scale down could be much more aggresive
I.II.V Region Spillover#
Let's focus on the regions us-east-1 and us-east-2 by selecting them as the Group Values in Fields [Advanced]:
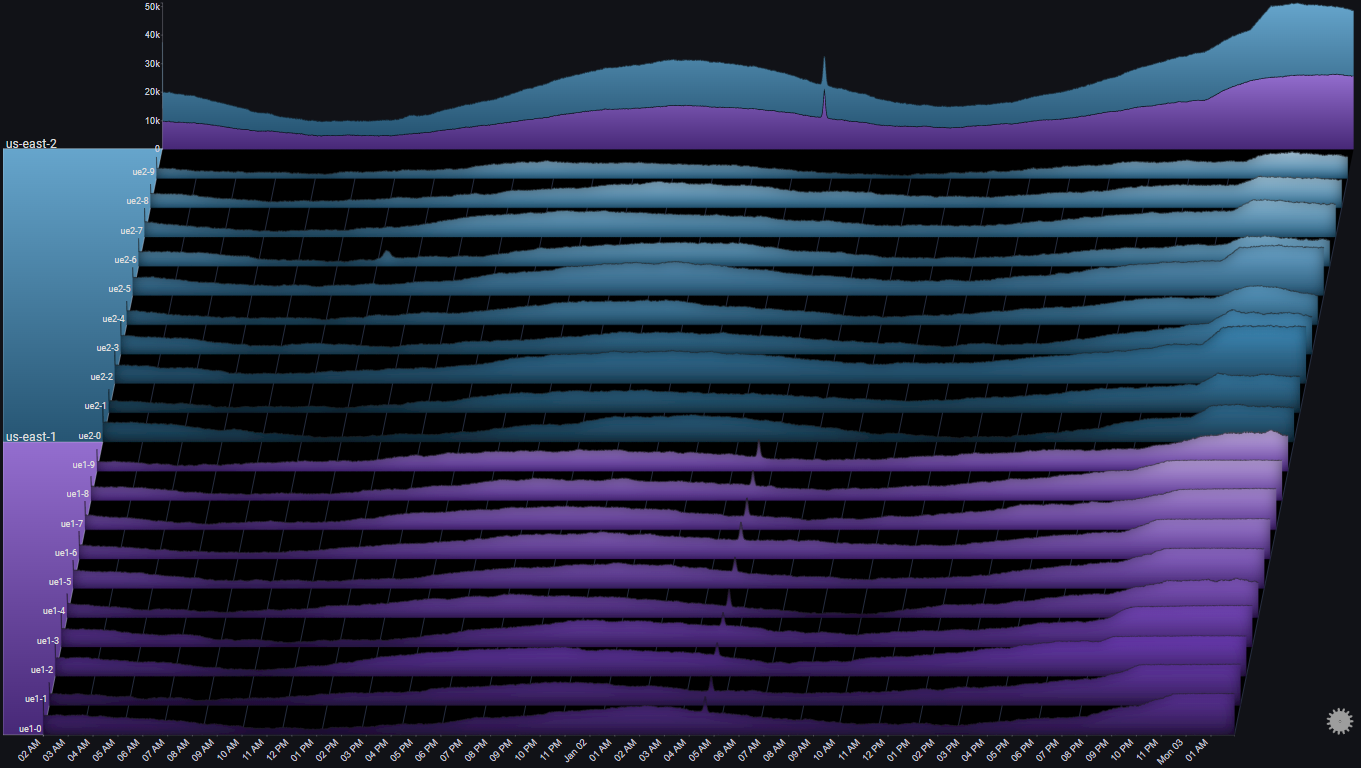
By looking at the Totals chart we can observe the following:
- At around 20:00 Jan 02, us-east-1 saw a gradual increase in request volume
- About an hour later, us-east-2 saw a sharp increase in request volume
By looking at the series charts we can observe the following:
- At around 21:00 Jan 02, the request volume to us-east-1 started plateauing
The above observations might lead us to the following conclusions:
- The servers in us-east-1 reached some capacity threshold at 21:00
- At that point, traffic started to spill over to us-east-2
It might be interesting to change the Totals chart's stack mode to Stacked100, to see the relative traffic distribution between the two us-east regions:
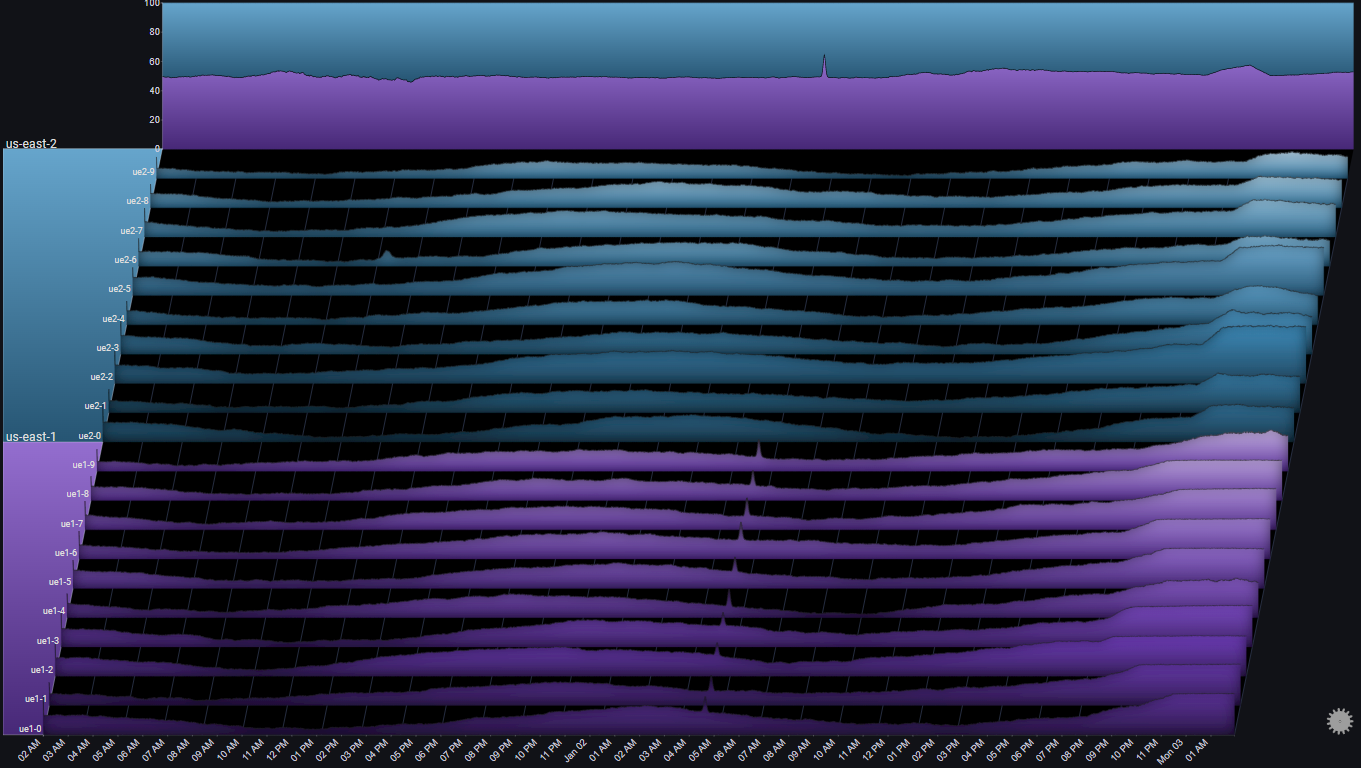
This shows us that the traffic distribution between the two us-east regions is roughly equal.
One of the regions (us-east-1) started getting a bigger relative share of the traffic, but it was re-balanced after an hour or so
II. Mortality Rates#
The following example shows the mortality rates in France between 1816 and 2016, by gender
It is based on the amazing visualization created by Kieran Healy:
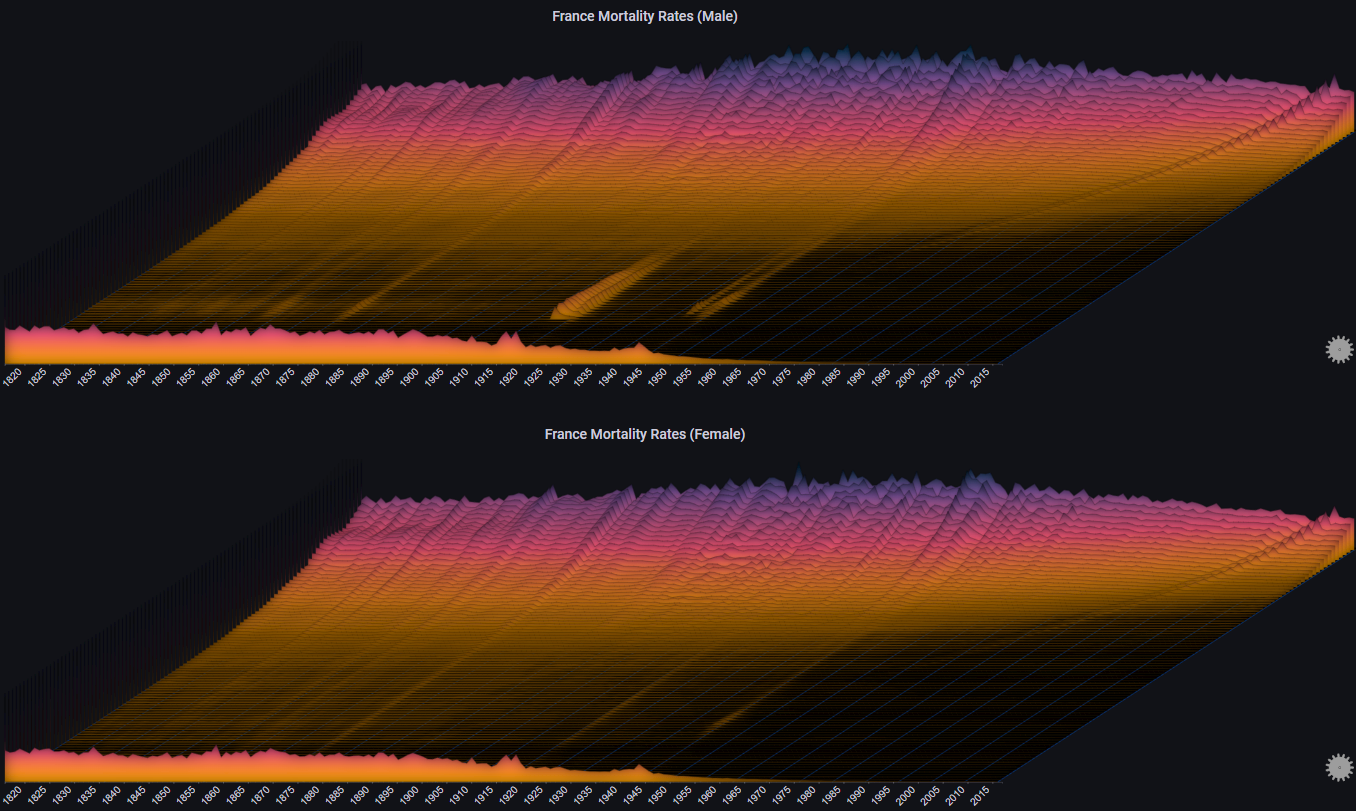
Note
The chart labels have been disabled for clarity. Each chart represents a single age cohort, starting from 0-1 at the bottom to 95 at the top
The plot allows us to immediatly observe events such as world wars and the 1918 influenza pandemic, as well as the considerable decline in infant mortality
By switching the max Y type to Local we get a different representation, which makes it easier to see trends for each individual age cohort (at the cost of losing the ability to compare values across different age cohorts):
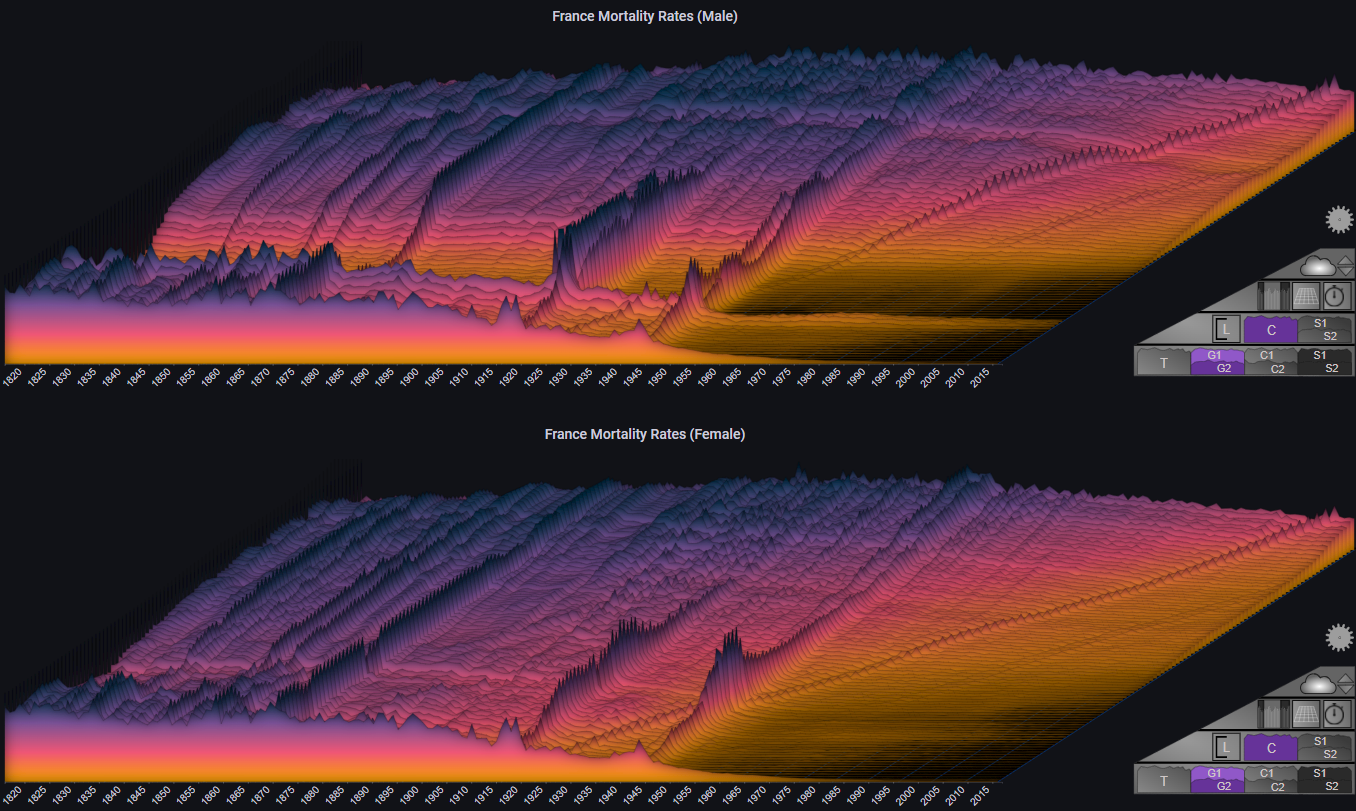
We can also decide to group certain ages, and represent that in the plot:
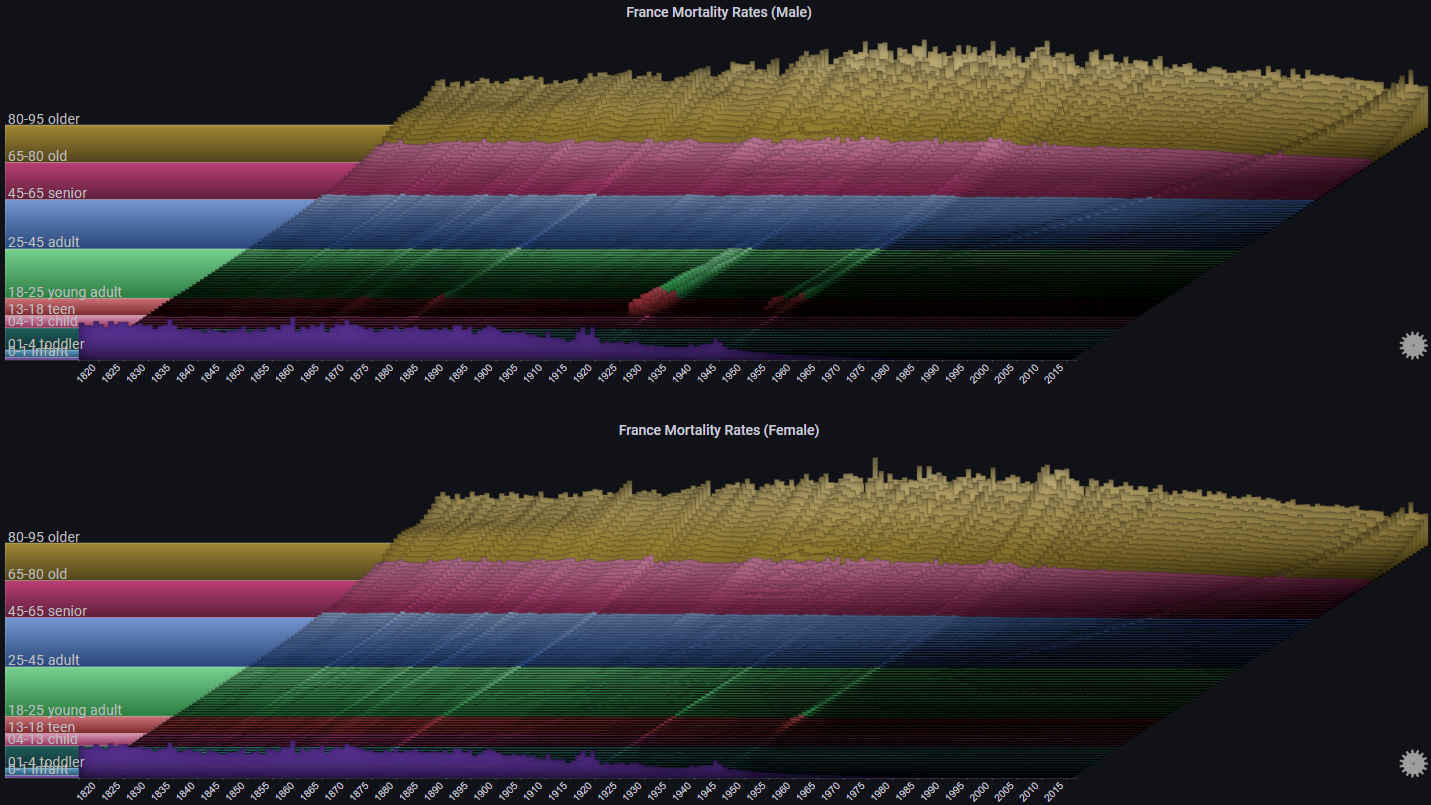
By switching the max Y type to Group we can see trends for each age cohort relative to its defined group:
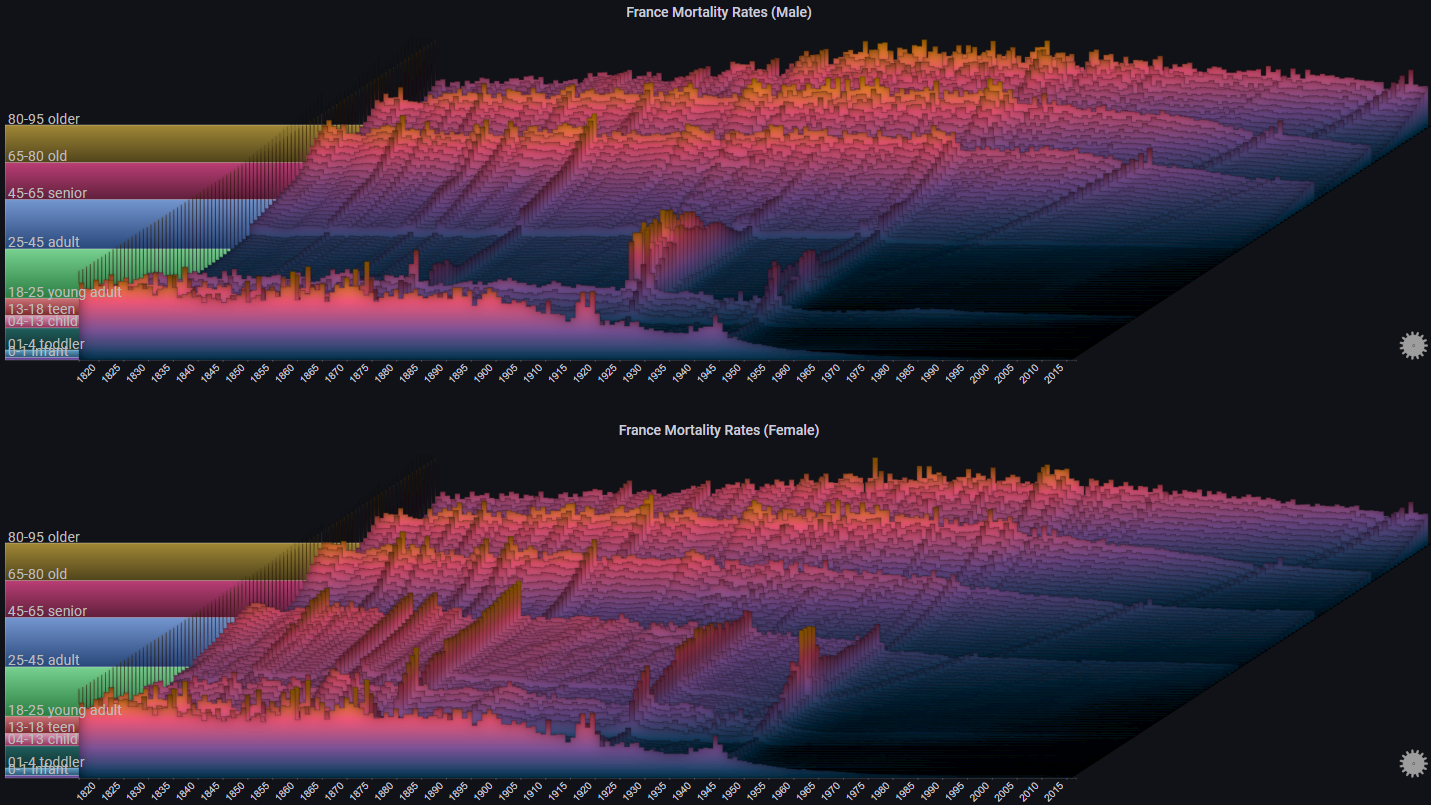
Some more styling options:

III. Covid19 Cases#
The following example shows the number of daily reported Covid-19 cases in the United States, by state:
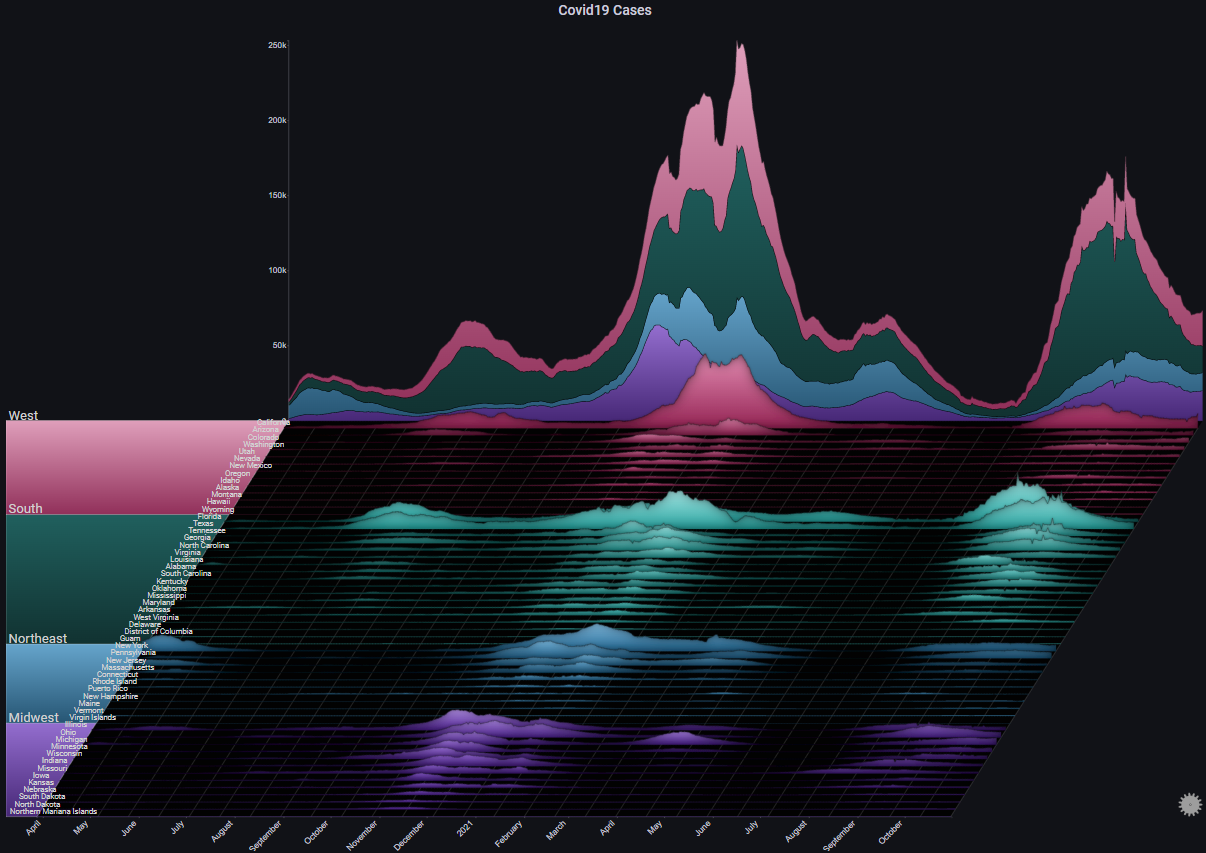
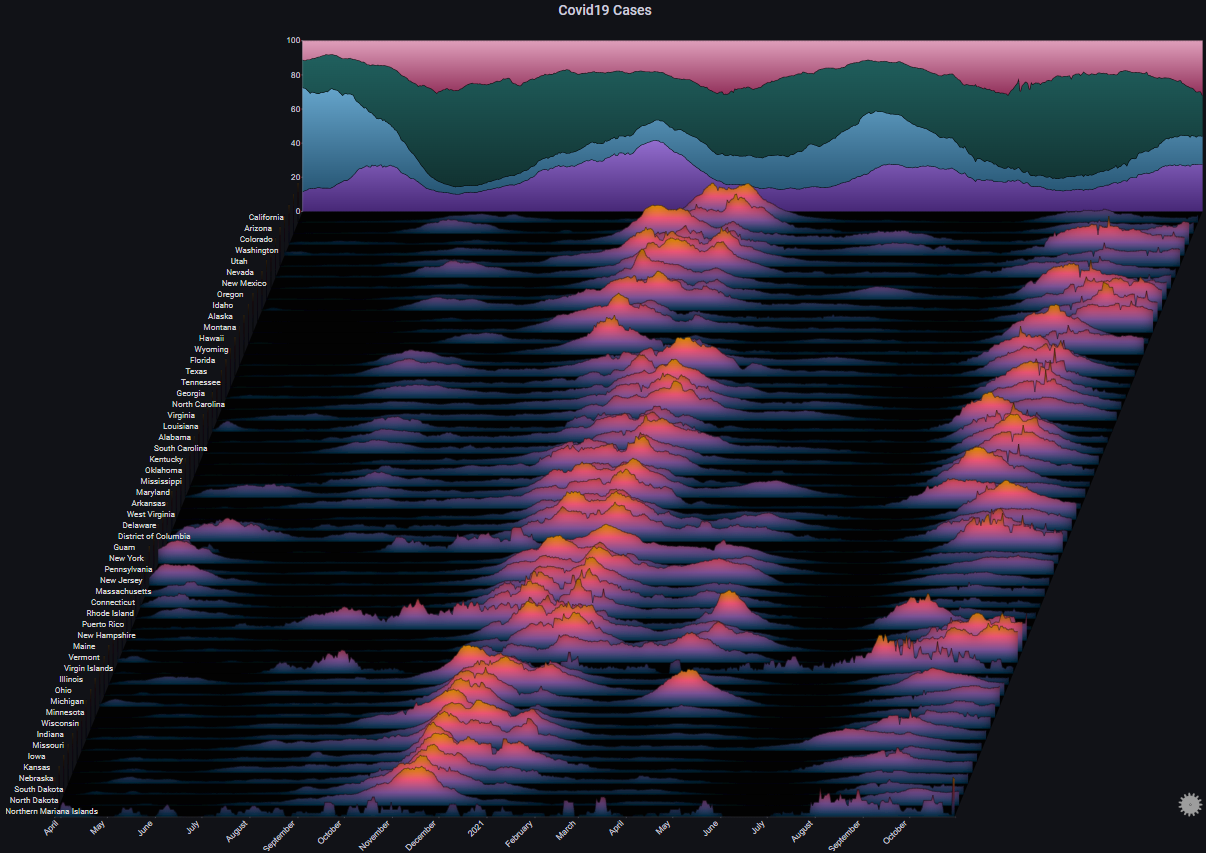
By switching the max Y type to Local we get a different representation which shows us the trend in each specific state (each chart's Y-axis has its own scale):
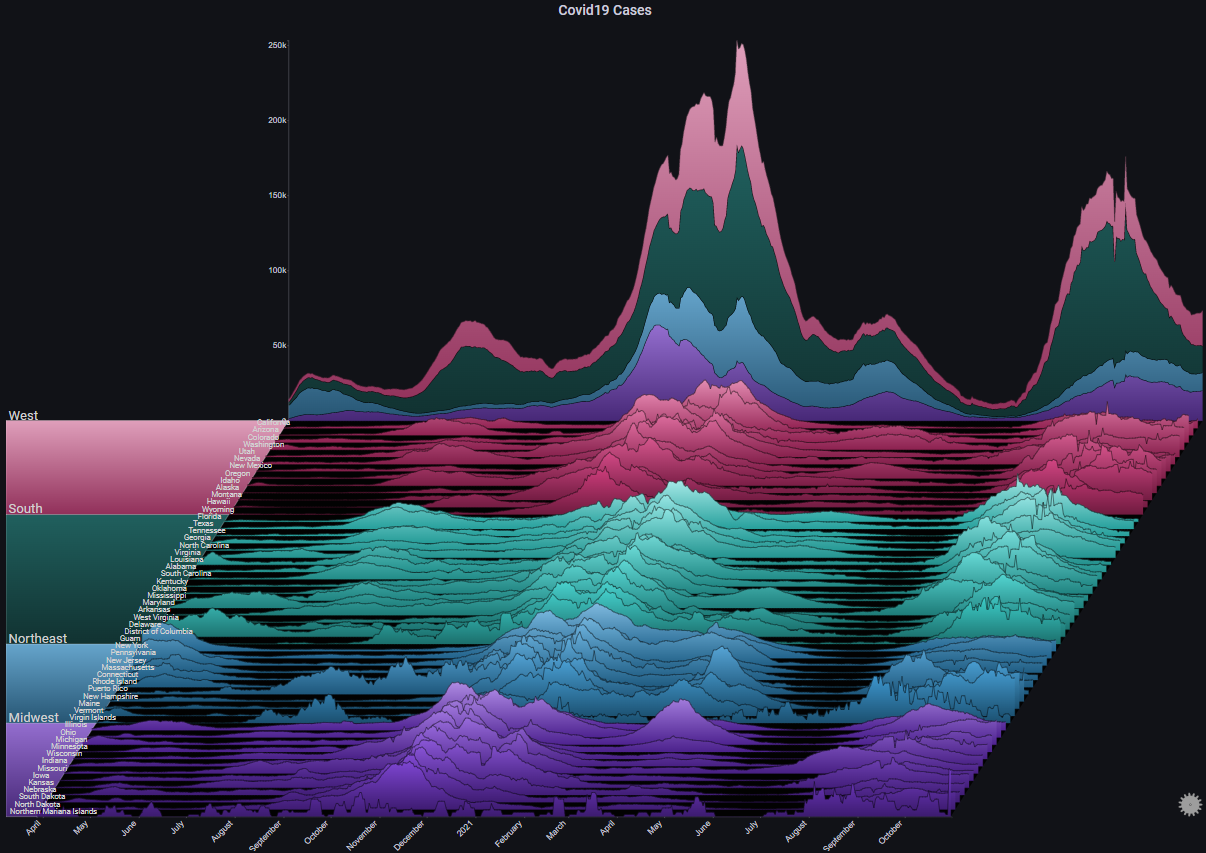
By enabling Fog we can highlight the peaks in the plot. Since we're using Local for max Y type, the Fog shows us the alignment of the peaks across all charts (basically, the peaks of the Covid-19 infection waves):
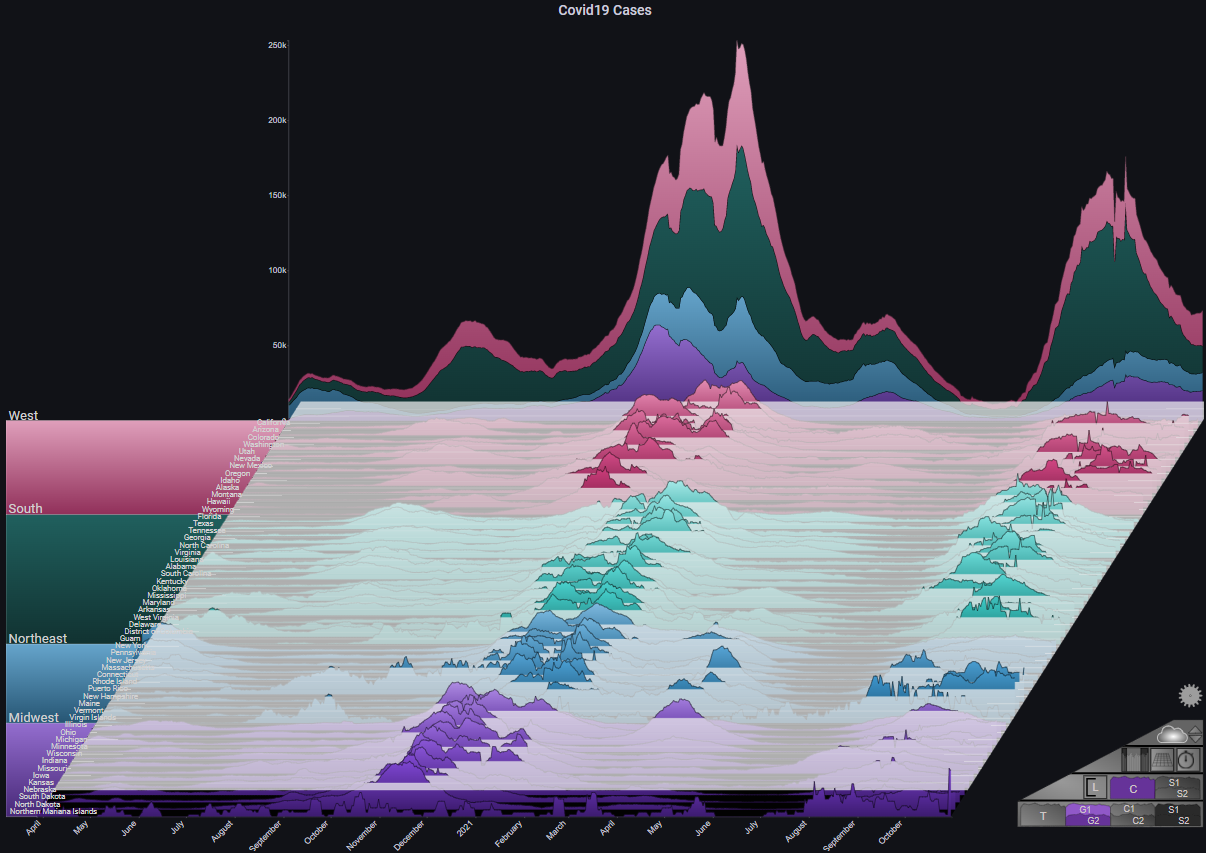
Some more styling options:
III. Lots of Charts#
The following examples showcases how Sierra Plots are useful for visualizing high-cardinality datasets
III.I 200 Servers#
The following example shows request rates across a 24 hour period (with 5 minute bins) for 200 servers across 5 different regions
It shows that even with a very large number of charts, overall trends and abnormal behaviours are still easy to spot:
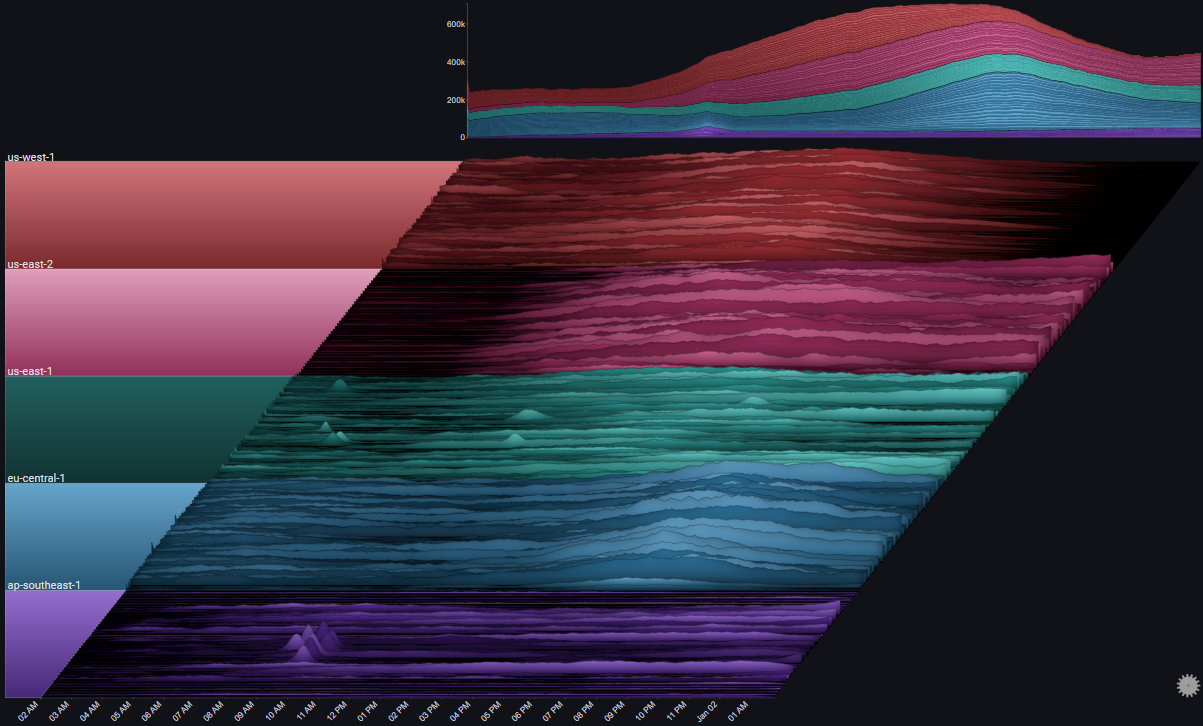
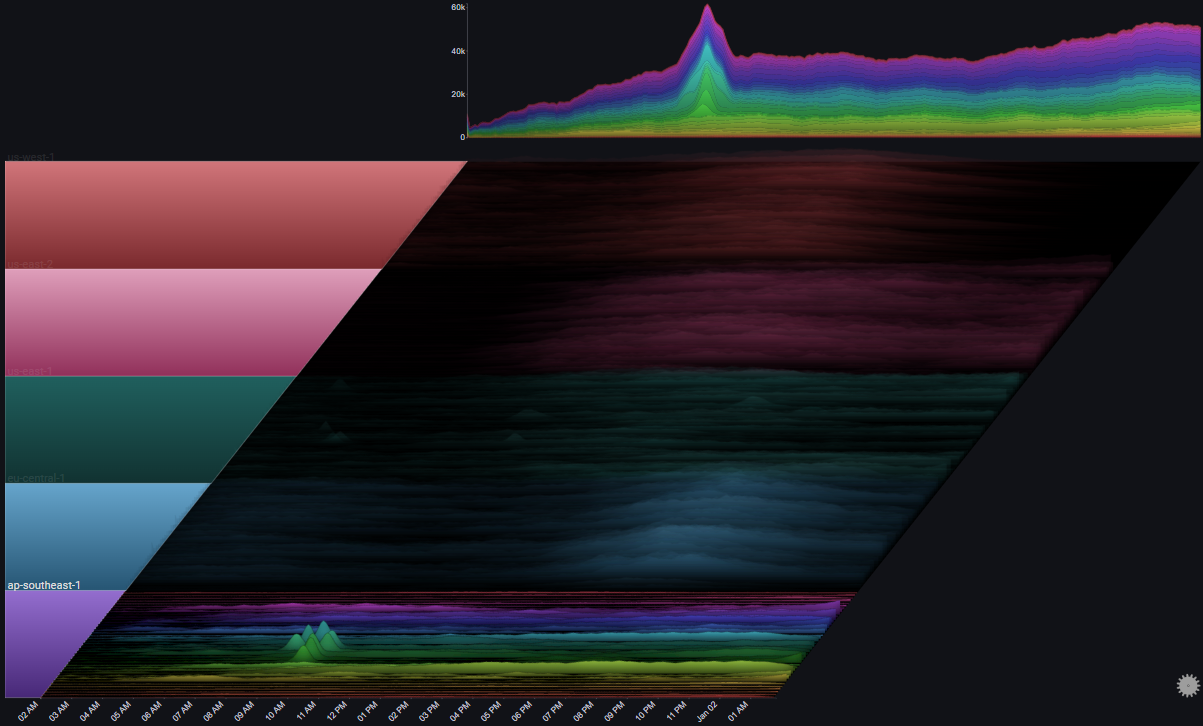
III.II 2000 Servers#
Let's get a little crazy...
The following example shows request rates across a 12 hour period (with 5 minute bins) for 2000 servers across 5 different regions
Even now, trends and outliers are still readily apparent